Denormalizing via embedding when migrating relational data from SQL to Cosmos DB
When migrating from a relational database (e.g. SQL Server) to a NoSQL database, like Azure Cosmos DB, it is often necessary to make changes to the data model to optimize it for the NoSQL use-cases.
One of the common transformations is denormalizing the data by embedding all of the related sub-items (when the sub-item list is bounded/limited) within one JSON document (e.g. including all of the Order Line Items within their Order).
In this post we look at a few options for performing this type of denormalization using Azure Data Factory or Azure Databricks.
For general guidance on data modeling for Cosmos DB, please review “Data modeling in Azure Cosmos DB”.
Update February 3, 2020: Please see the new official Azure Cosmos DB documentation covering the same scenario Migrate one-to-few relational data into Azure Cosmos DB SQL API account.
Example Scenario
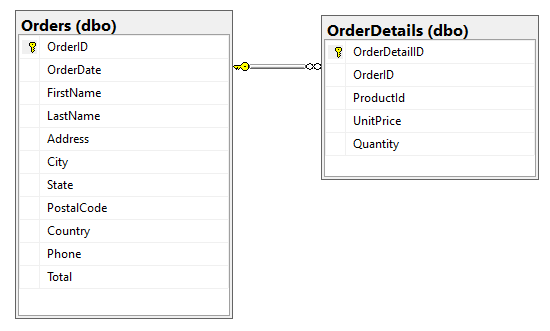
Let’s say we have the following two tables in our SQL database, Orders and OrderDetails, and we want to combine this one-to-few relationship into one JSON document during relational data migration to Cosmos DB via embedding.
We can create the proper denormalization in a T-SQL query using “FOR JSON” like this:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
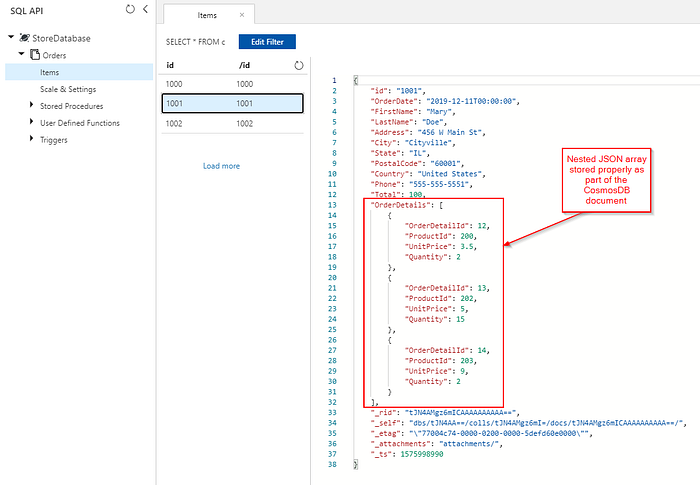
Ideally, it would be great to use a single Azure Data Factory (ADF) Copy Activity to query SQL as the source and write the output directly to Cosmos DB sink as proper JSON objects. However, currently, it is not possible to perform the needed JSON transformation in one Copy Activity. So, if we try to copy the results of the query above into a Cosmos DB SQL-API collection, we will see the JSON of the OrderDetails sub-items as a string property of our document (instead of a proper JSON array):


We can workaround this current limitation in one of the following ways:
- Use Azure Data Factory with two Copy Activities: (1) get JSON-formatted data from SQL to a text file in an intermediary blob storage location, and (2) load from the JSON text file to the Cosmos DB collection.
- Use Azure Databricks Spark to read from SQL and write to Cosmos DB after applying proper schema with from_json().
- There is also a great blog post from Azure Cosmos DB showing how to use Azure Databricks with Python to perform the embedding transformation - see “Migrating Relational Data with one-to-few relationships into Azure Cosmos DB SQL API”.
Let’s look at the first two approaches in a bit more detail.
ADF with Two Copy Activities
Although with the current ADF Copy Activity capabilities we cannot embed OrderDetails as a JSON-array in the destination Cosmos DB document, we can workaround the issue by using two separate Copy Activities.
Copy Activity #1: SqlJsonToBlobText
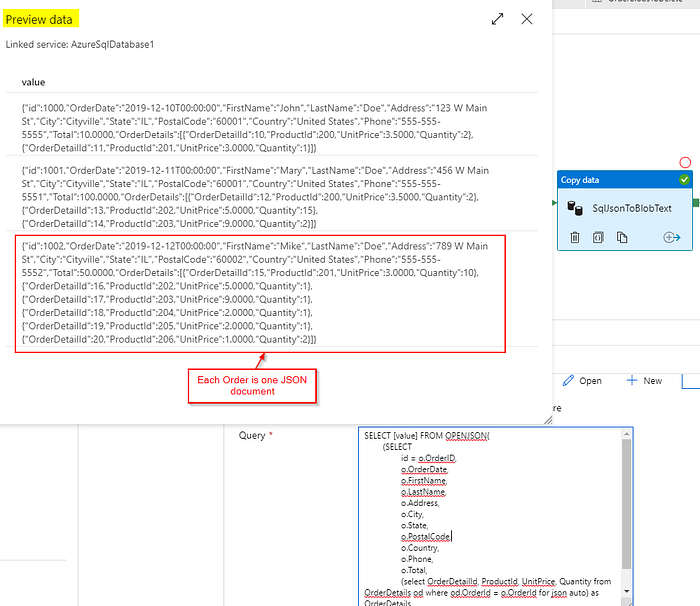
For the source, we use a SQL query to get the result set as a single column with one JSON object (representing the Order) per row using SQL Server’s OPENJSON and FOR JSON PATH capabilities:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
For the sink of the SqlJsonToBlobText copy activity, we choose “Delimited Text” and point it to a specific folder in Azure Blob Storage with a dynamically generated unique file name (e.g. ‘@concat(pipeline().RunId,’.json’).
Since our text file is not really “delimited” and we do not want it to be parsed into separate columns using commas and want to preserve the double-quotes (“), we set “Column delimiter” to a Tab (“\t”) [or another character not occurring in the data] and “Quote character” to “No quote character”.
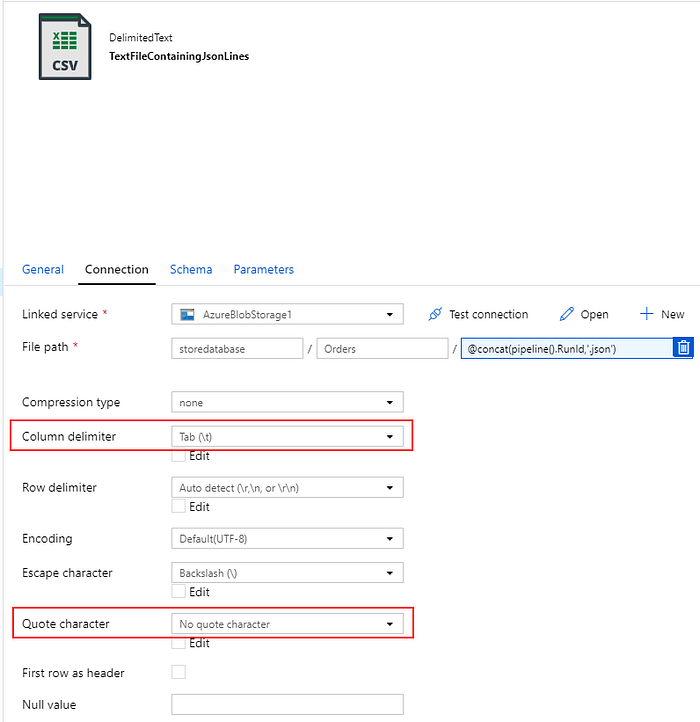
Copy Activity #2: BlobJsonToCosmos
Next, we modify our ADF pipeline by adding the second Copy Activity that looks in Azure Blob Storage for the text file that was created by the first activity, and processes it as “JSON” source to insert to Cosmos DB sink as one document per JSON-row found in the text file.
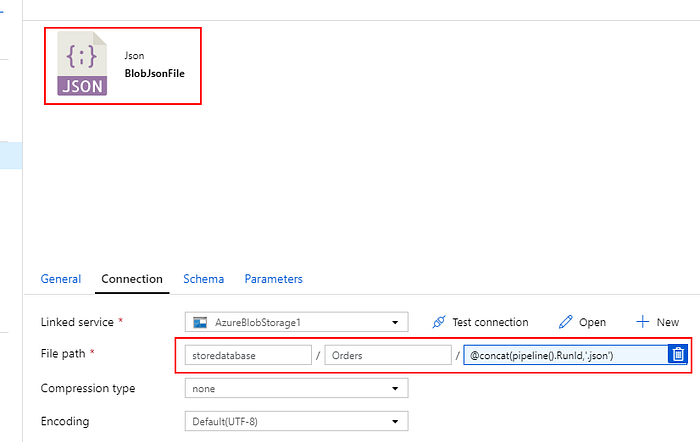
Optionally, we also add a “Delete” activity to the pipeline so that it deletes all of the previous files remaining in the /Orders/ folder prior to each run. Our ADF pipeline now looks something like this:
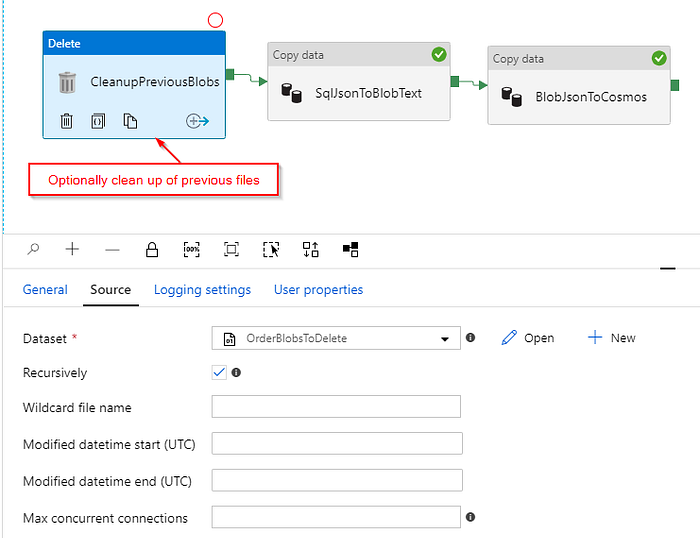
After we trigger the pipeline above, we see a file created in our intermediary Azure Blob Storage location containing one JSON-object per row:

We also see Orders documents with properly embedded OrderDetails inserted into our Cosmos DB collection:
Azure Databricks Spark with from_json()
As another approach, we can use Azure Databricks Spark to copy the data from SQL Database source to Cosmos DB destination without creating the intermediary text/JSON files in Azure Blob Storage.
NOTE: For clarity and simplicity, Scala code snippets below include dummy database passwords explicitly inline, but you should always use Azure Databricks secrets.
First, we create and attach the required SQL connector and CosmosDB connector libraries to our Azure Databricks cluster and restart the cluster to make sure libraries are loaded.

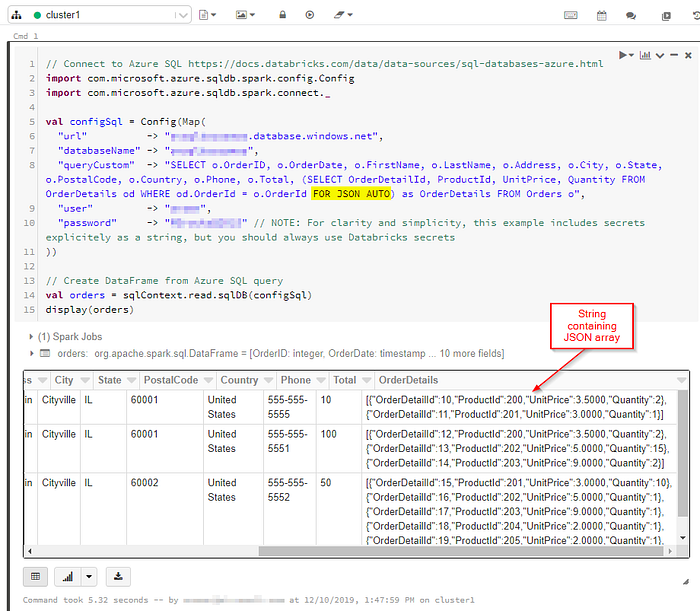
Next, we get the results of the SQL query with “FOR JSON” output into a DataFrame:
// Language: Scala// Connect to Azure SQL https://docs.databricks.com/data/data-sources/sql-databases-azure.html
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
Next, we connect to our Cosmos DB database and collection:
// Language: Scala// Connect to Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Configimport org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configCosmos = Config(configMap)
Finally, we define our schema and use from_json to apply the DataFrame prior to saving it to the CosmosDB collection.
// Language: Scala// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)display(ordersWithSchema)// Save nested data to Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
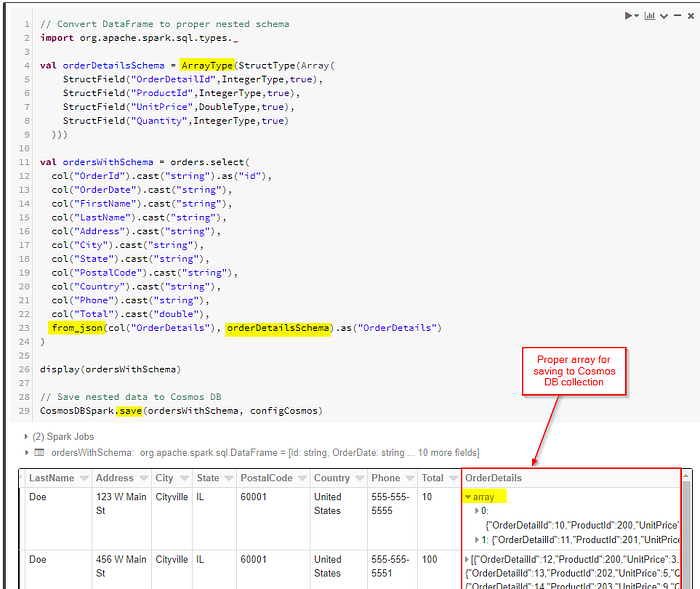
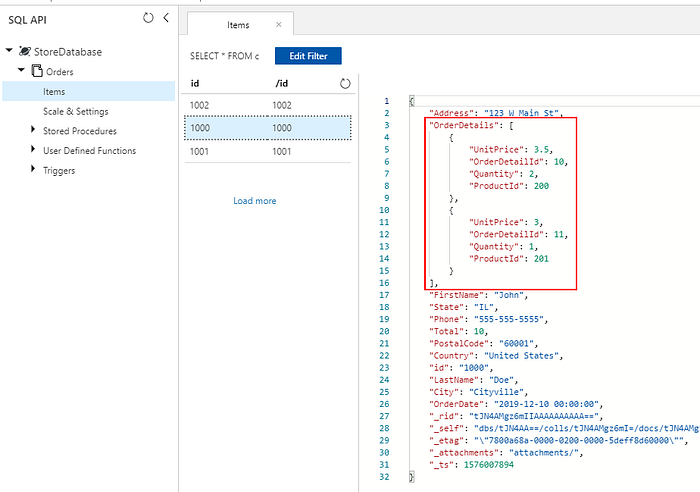
At the end, we get properly saved embedded OrderDetails within each Order document in Cosmos DB collection:
Next Steps
- See Migrating one-to-few relational data into Azure Cosmos DB SQL API account
- For Databricks with Python approach see “Migrating Relational Data with one-to-few relationships into Azure Cosmos DB SQL API”.
- Learn more about “Data modeling in Azure Cosmos DB”.
- Dive in with “How to model and partition data on Azure Cosmos DB using real-world example”.
Thank you!
Please leave feedback and questions below or on Twitter https://twitter.com/ArsenVlad
